Modeling the Dynamics of EV Adoption: An Agent-Based Approach
Agent-Based Modeling can simulate heterogeneous household dynamics and neighborhood variables that influence EV adoption. We demonstrate these methods looking at EV adoption in California with and without the Inflation Reduction Act tax credits.


Consumer adoption of electric vehicles (EVs) is critical for decarbonization in California, across the US, and worldwide. For researchers, planners, and policymakers, the central question isn’t just how many EVs; it’s who adopts, when, and why. Our analysis shows that sustained federal EV tax credits accelerate adoption momentum by strengthening neighborhood “peer effects,” while the repeal of these credits slows growth and deepens regional disparities in adoption rates. To capture these dynamics, we built an agent-based model (ABM) of California households that links policy, technology costs, and social influence. The model in its current form lacks rigorous empirical grounding, and its results should not be interpreted as confident projections. Nonetheless, the framework — an active work in progress — clarifies how incentives, technology, infrastructure, and psychology interact to shape adoption at the local level, thereby demonstrating a key example of emergent complexity. These insights can guide effective, equitable clean energy policy.
Today’s forefront of adoption modeling — and what ABM adds
There’s a healthy toolkit today for studying vehicle choice and technology adoption. Discrete-choice models (like multinomial or mixed logit) are the workhorses: they link purchase decisions to prices, income, and attributes in a way that’s interpretable and great for policy comparisons at the time of purchase. Diffusion models fit classic theoretical adoption trajectories (e.g., S-shaped curves) and are handy for quick, big-picture forecasts. Systems optimization, integrated assessment, and energy-economy models look across the whole energy system — electricity, fuels, industry — to tell us what’s economically optimal for a given set of assumptions. Across this modeling toolkit, when data are thin, expert judgment can help fill gaps, especially for very new technologies.
Despite this robust suite of modeling options, each of these approaches carries with it a specific set of limitations. Choice models can struggle to capture social and neighborhood effects or feedback loops over many years without much scaffolding. Diffusion curves tell us that adoption might accelerate, but they don’t tell us who moves first or how a specific policy or charging build-out shapes the curve. System models are fantastic for system-wide consistency, but the detail of household behavior is often simplified, smoothing over narratives that might be informative and potentially missing out on emergent complexity. Finally, although expert judgement is fast and often reliable, it can be subjective or underinformed — especially when the market is moving quickly.
Agent-based modeling complements all of this. Instead of a single “representative consumer,” ABM builds a population of household agents with diverse incomes, housing situations, access to charging, preferences, and more. Households respond to policy and technology — but also to each other. For example, when more neighbors drive EVs or chargers become more visible, these perceptions can accelerate adoption. Because the model runs year by year, it naturally captures feedback cycles and path dependence: incentives spur purchases, purchases change what people see on their streets, and that visibility influences future purchases. In short, ABM is built for heterogeneity, social dynamics, and time. The downsides of ABM are that more data are required to characterize the agents, and calibration can be more difficult given the non-linear and path-dependent nature of the outputs.
How the ABM works
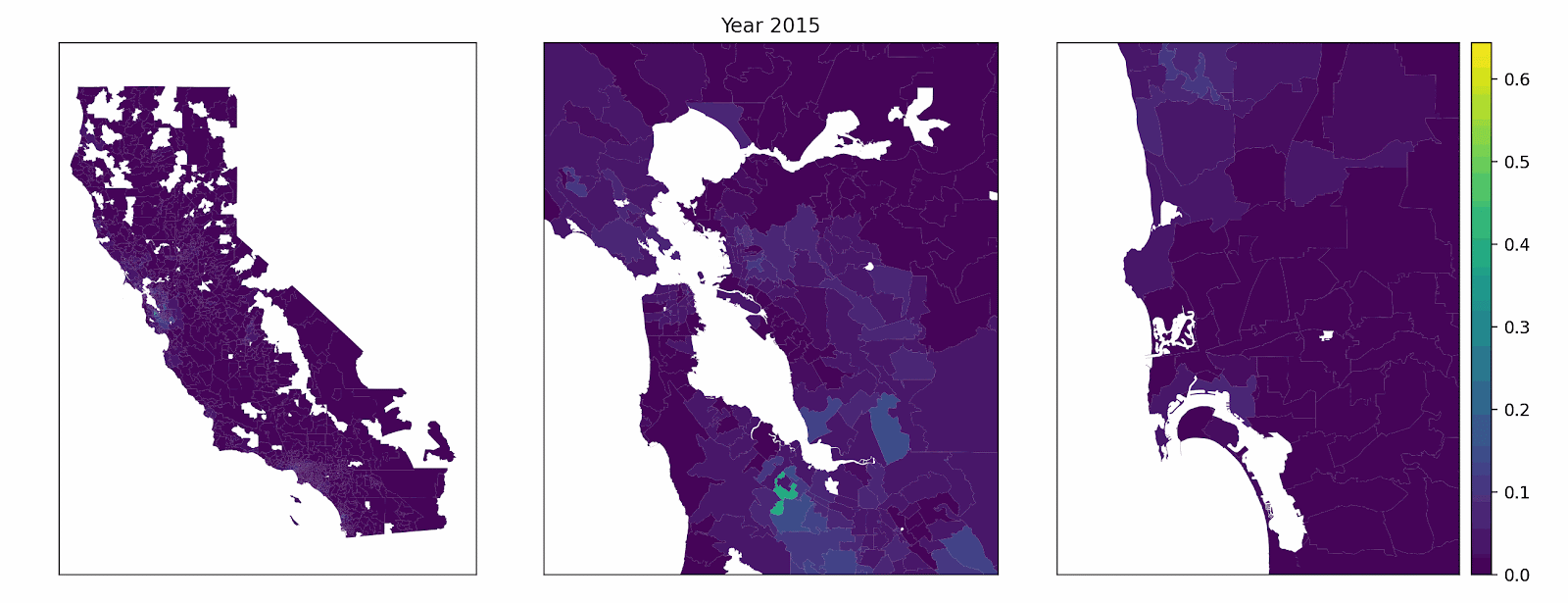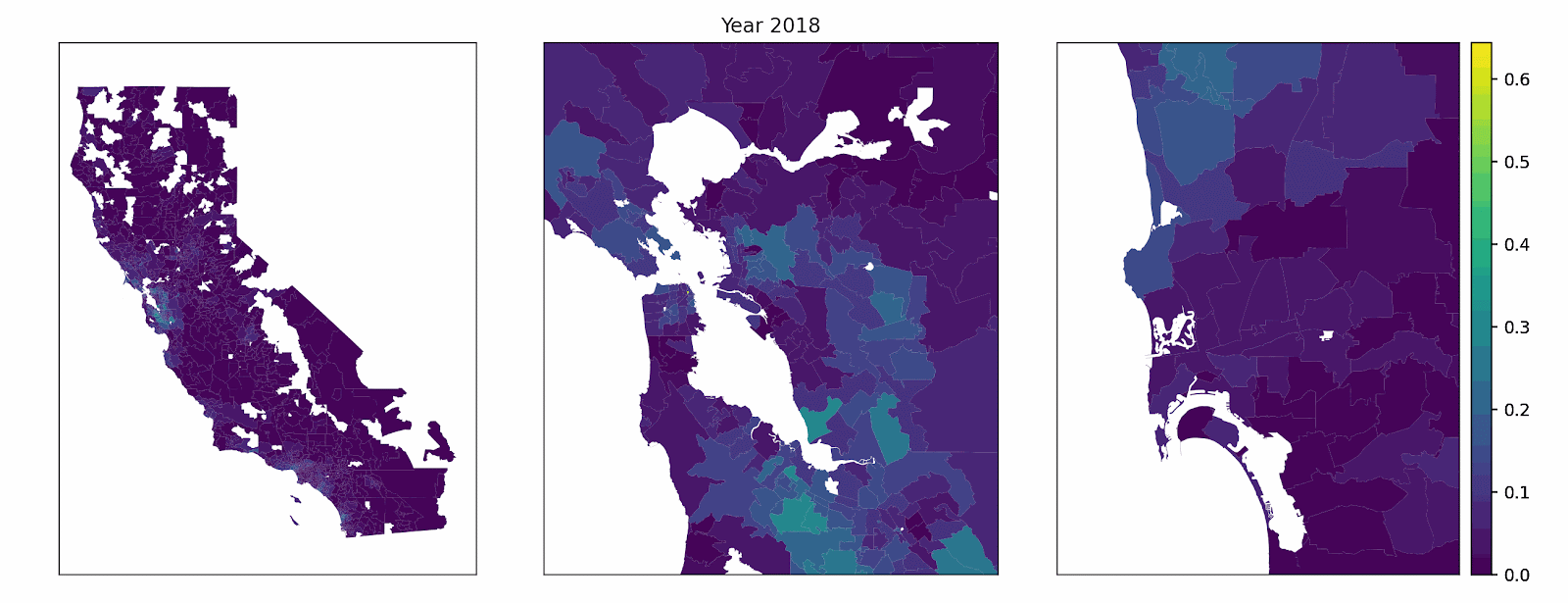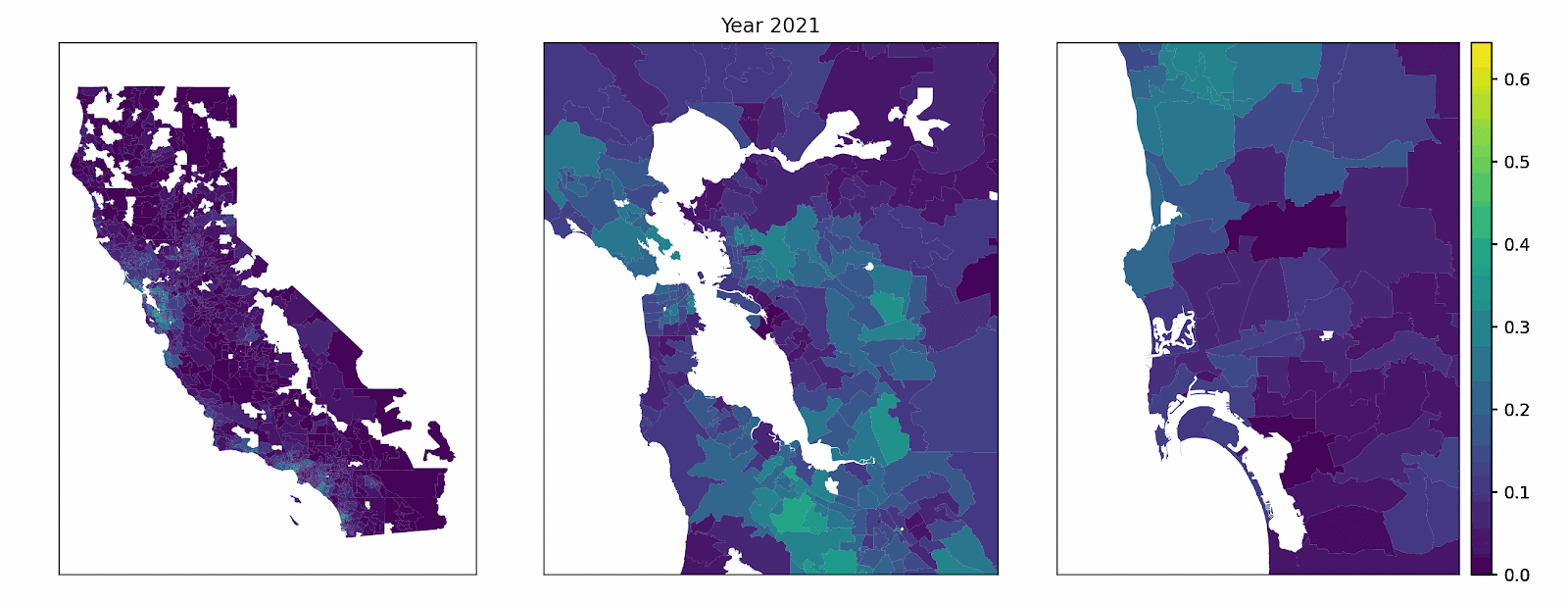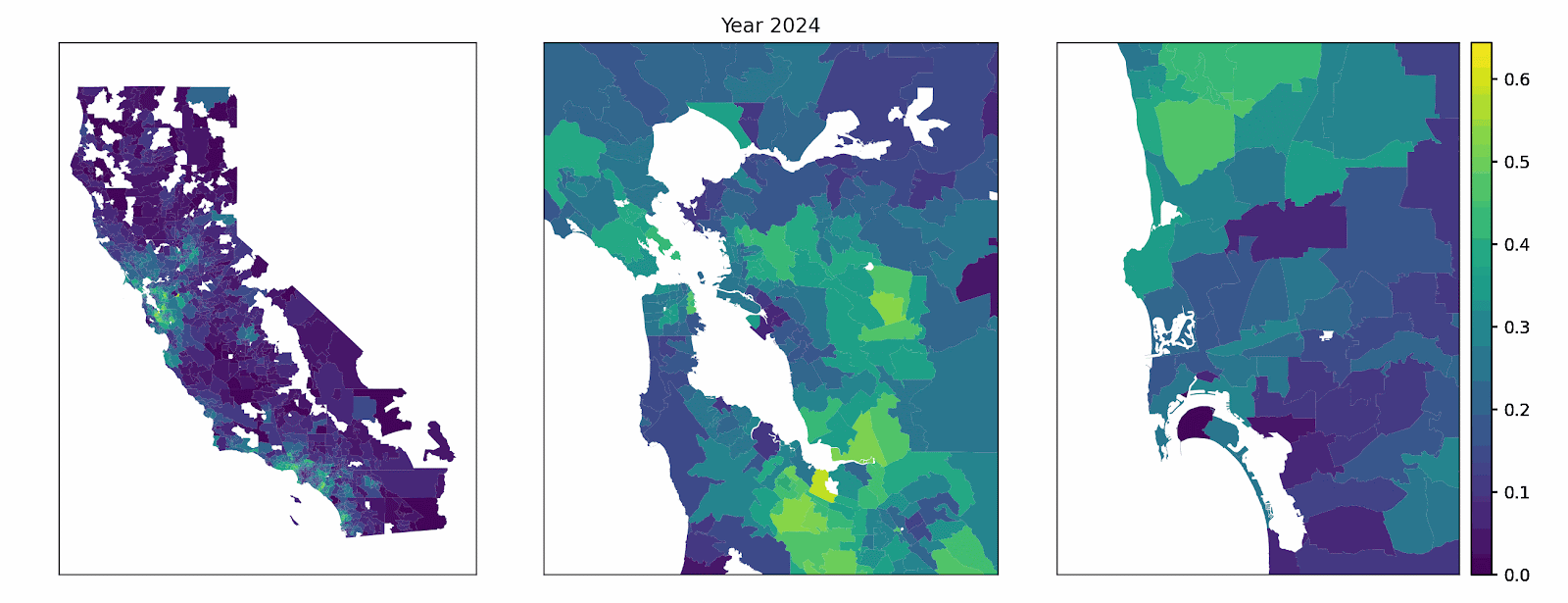
Our model represents a synthetic population of California households. Each year, a subset of vehicles is randomly chosen for replacement (multiple vehicles can be replaced by the same household in the same year) using zip code quota constrained, age-weighted random selection. When a given household buys a new vehicle in the model, it weighs the appeal of several powertrains — gasoline, hybrid, plug-in hybrid, and battery electric — based on things like total ownership cost (using income-dependent discounting and heterogeneous driving patterns), home and public charging access, and how common EVs already are nearby. An example decision factor, public level 2 charging access by zip code, is shown below.
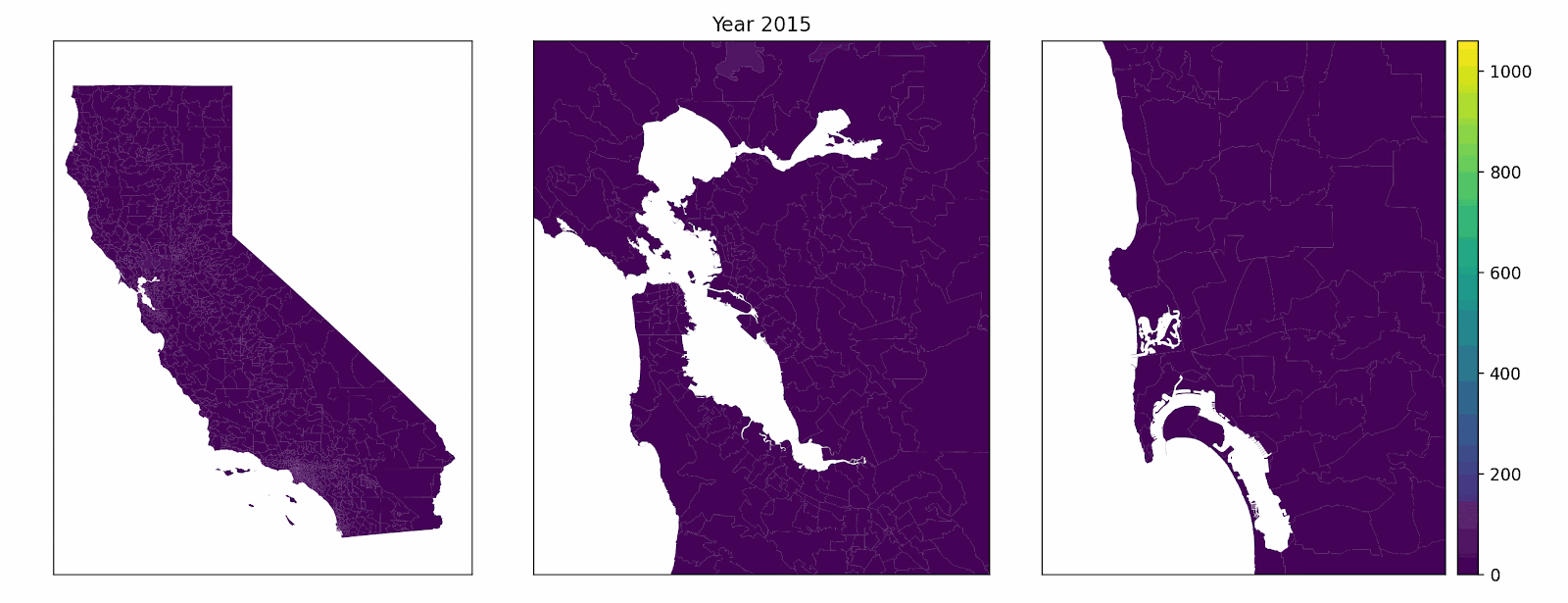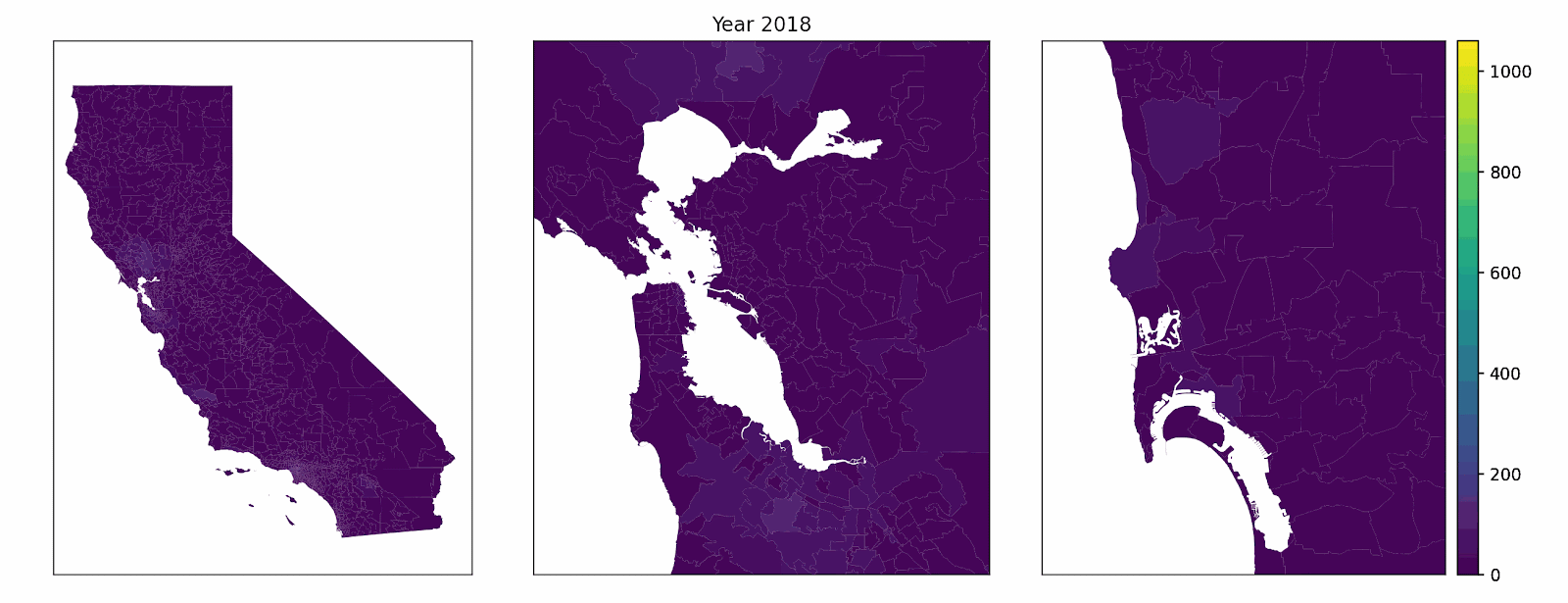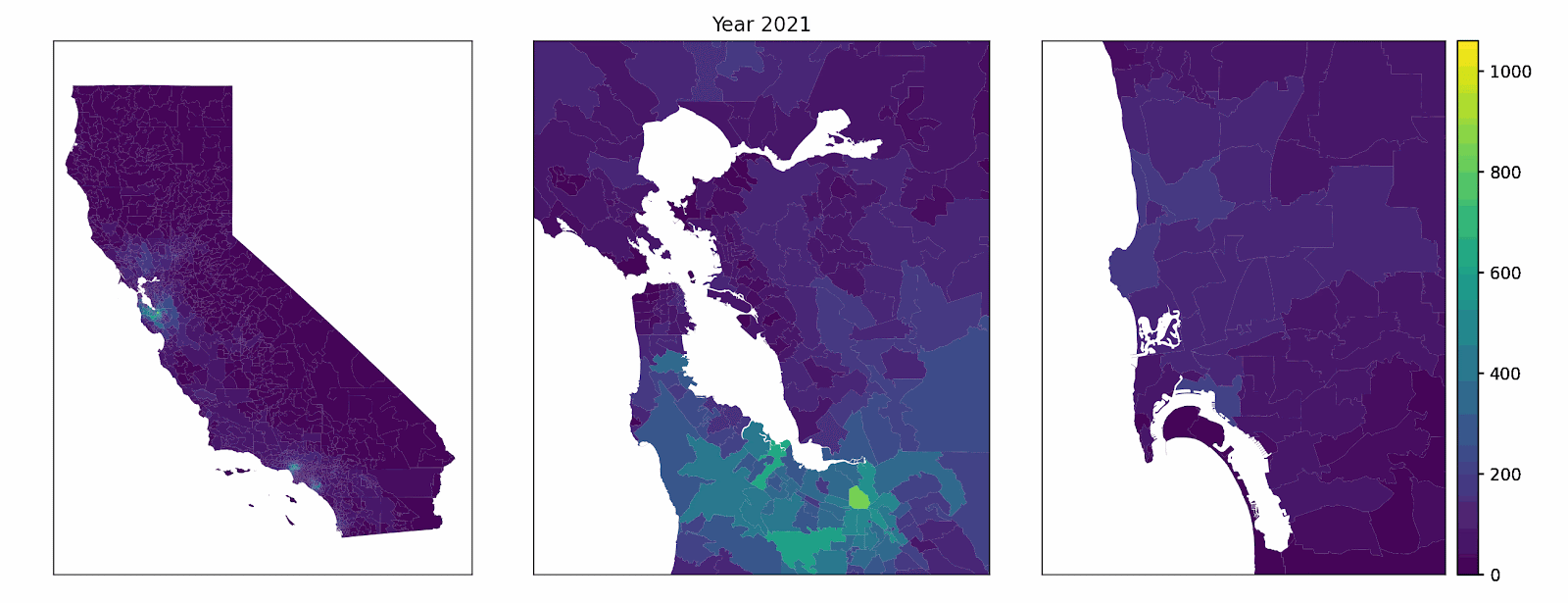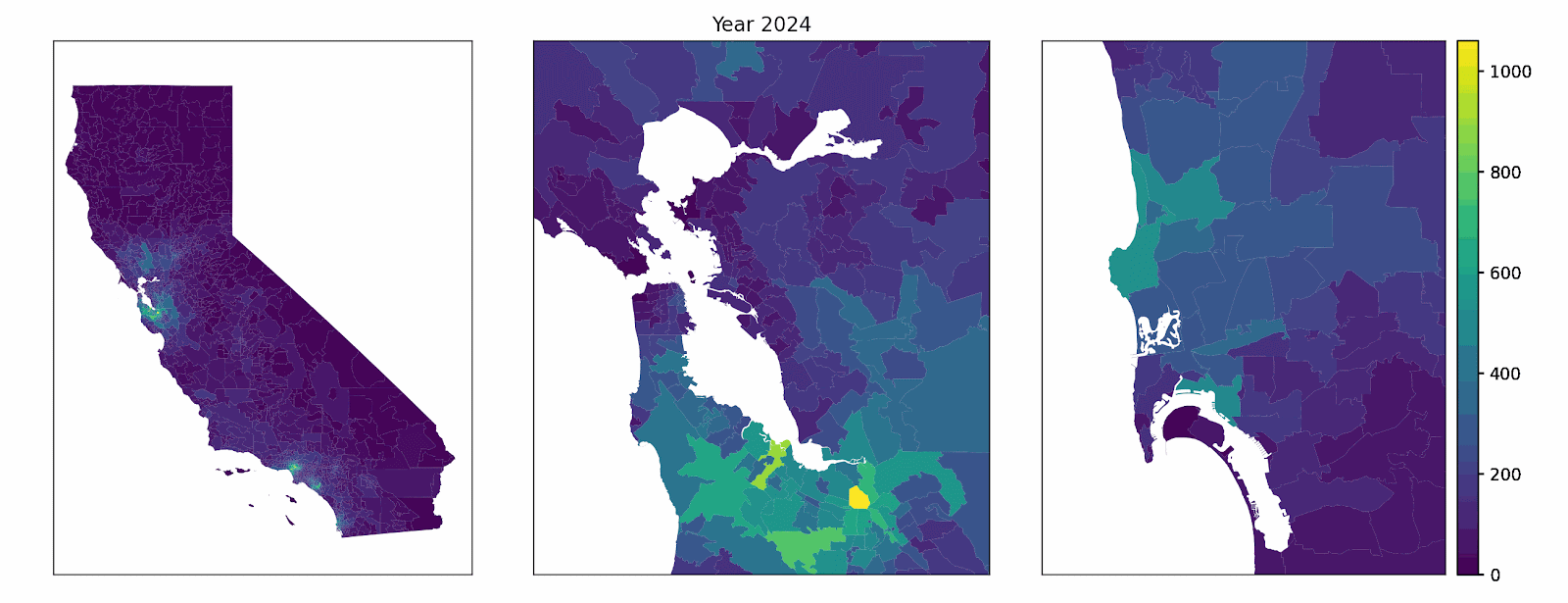
The final decision isn’t purely mechanical. Rather, a probabilistic rule is used where more attractive options get more weight, reflecting the reality that not every household with the same characteristics makes the same choice. Once choices are made, the vehicle fleet updates and the neighborhood picture changes. These changes, in turn, affect the context for the next year’s decision-making. Over time, adoption patterns emerge across zip codes, not because an S-curve is externally imposed, but because individual choices are built from the bottom up. High-level complexity emerges from stochastic, rules-based individual choices.
Calibrating the model: teaching it to learn from data
To be useful, a model like this needs to learn from evidence. Most existing ABMs of low-carbon technology adoption rely on survey data or expert elicitation to set model parameters. In this project, the key parameters target the importance of different decision factors to households choosing between powertrains. As with all modeling, varying approaches each introduce their own forms of bias. Ideally, model parameters would be learned from historical adoption trends; this is where simulation-based inference (SBI) comes in. SBI proceeds in three broad steps: it (1) simulates the model with many iterations under different parameter settings, (2) summarizes what those simulated worlds look like, and (3) uses machine learning to determine which parameter values are most consistent with the real world. The output isn’t just a single “best” setting; it’s a distribution that reflects uncertainty with multiple possibilities.
This is an active research frontier. Applying SBI to a high-dimensional, stochastic ABM like this is novel and technically challenging. The SBI pipeline has progressed substantially, but it hasn’t yet produced parameter estimates reliable enough for policy analysis. Instead, this work lays the rails for eventual calibration of such a complex ABM using SBI. More information on the SBI approach being pursued, and the current state of its implementation, can be found in the slide deck linked at the end of this post.
In the meantime, we settled for a sensible approach to test the core ABM functionality. By visually matching the model’s statewide adoption trajectory to ground truth in California from 2015 to 2024, we constructed a feasible parameter set: an interim model calibration grounded in aggregate data. With this “manual SBI” baseline, we can run scenario and sensitivity analyses.
Simulating the impact of IRA repeal
Using the feasible parameter set, we simulate the future impact of the recent repeal of the EV tax credits: what would happen if federal EV purchase incentives continued through 2032 instead of ending in 2025? To make the results more informative (and realistic), we sweep a wide range of sensitivities around technology costs, vehicle attributes, charging infrastructure availability, and commodity prices. As a result, the model is dynamic instead of hinging on a single assumption, such as battery prices or fuel costs.
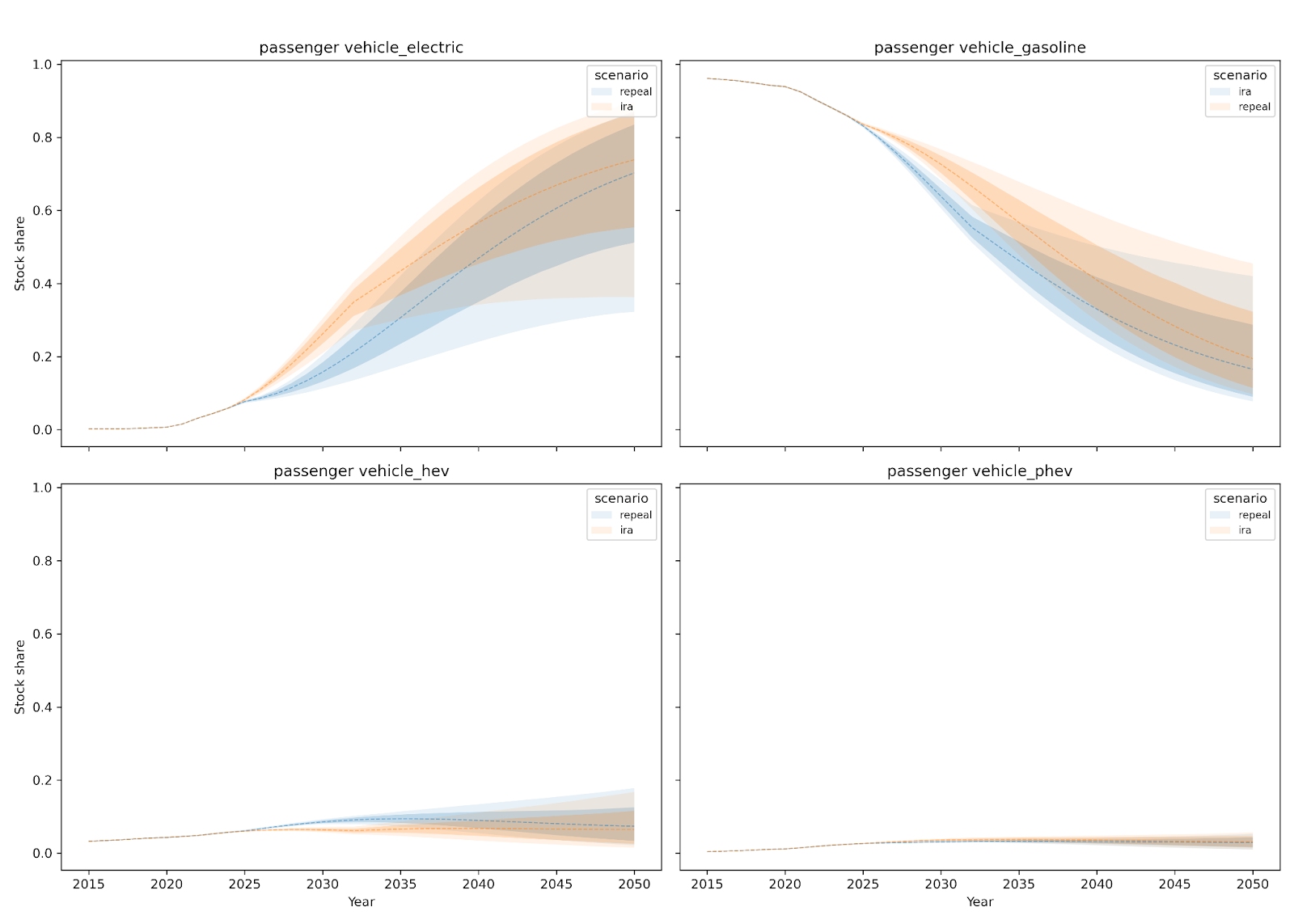
What emerges is intuitive yet informative: sustained credits would build adoption momentum more quickly and strengthen peer effects, in neighborhoods with and without high EV adoption today. Alternatively, if credits end early, statewide adoption still grows, but the curve flattens, the neighborhood clustering effect weakens, and regional adoption disparities widen. We find the most important sensitivity to be vehicle capital costs (which in turn are driven largely by future declines in battery costs). Thus, IRA repeal could have a greater second-order impact on adoption as domestic EV manufacturing stalls and EV prices remain elevated even after 2032, relative to the counterfactual scenario. The result sends a clear message: financial incentives, infrastructure development, technological advances, and social influence work together. All four have critical roles to play in a rapid and equitable EV transition.
The interactive viz didn’t load. You can open it directly:
or view a static preview below.
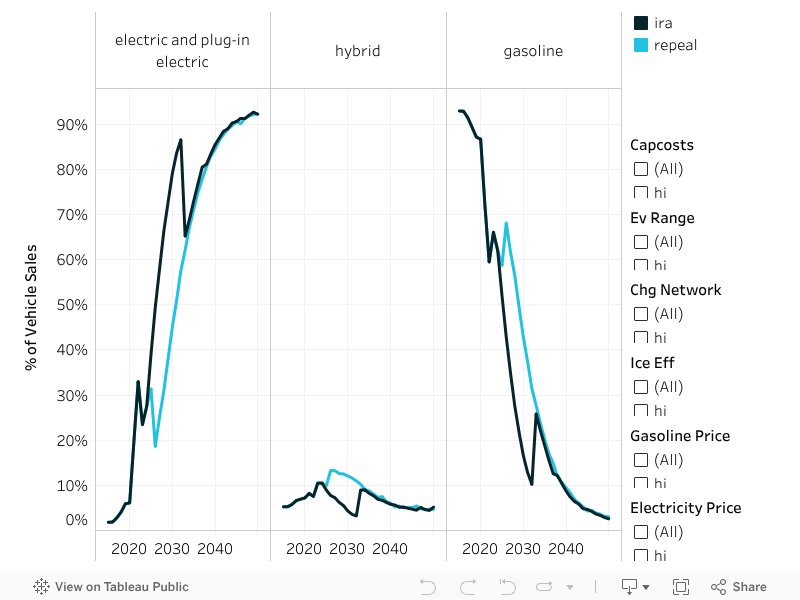
Figure 4. Annual Share of New Vehicle Sales in California by Technology Category, 2015–2050 (IRA vs Repeal).
What's next?
The next step is to refine the SBI pipeline by designing quality summary statistics, improving the neural network that links simulated worlds to parameters, and building trustworthy diagnostics. Once that’s in place, we’ll have parameters with uncertainty, not just point guesses, which makes the policy insights more robust.
A parallel and crucial task is generalization beyond EVs in California: the same ABM-plus-SBI approach can apply to other geographies and technologies (e.g., heat pumps or rooftop solar). Longer-term, the goal is to “close the loop” with system models — feeding behaviorally rich, spatially explicit demand into the energy-system planning tools that shape investment and infrastructure decisions.
Energy transitions are social as much as they are technical. By modeling households, neighborhoods, and time — not just averages — we can ask sharper questions about policy design and equity, and we can see why adoption accelerates in some places while it stalls in others. This study has focused on establishing this scaffolding. The work on inference is ongoing, and that’s part of the excitement: we’re building a framework that learns from data and speaks to the decisions in front of us.
Download the full presentation
About the author: Ari Ball-Burack is a third year PhD student in the Energy & Resources Group at the University of California, Berkeley, advised by Dr. Dan Kammen. His research works to incorporate key complexities, such as technological innovation and consumer adoption behavior, in energy system models and climate policy decision support tools. His current projects investigate decarbonization policy interactions at the national and global levels, distributional equity in electric vehicle charging infrastructure, representations of consumer adoption in multi-sector energy system models, and granular adoption modeling for low-carbon technologies. Ari graduated from Williams College, where he studied Computer Science and Physics, and received MPhil degrees in Advanced Computer Science and Environmental Policy from the University of Cambridge. Prior to joining UC Berkeley, he worked as a researcher at the Cambridge Institute for Sustainability Leadership. Concurrently with his PhD, he has worked for the World Bank and the County of Napa, and was a visiting researcher at the University of Chicago's Institute for Mathematical and Statistical Innovation.